{kind=link}
Description: PNG image
|
| From: | 张博洋 |
| Subject: | [Tinycc-devel] BUG: wide char in wide string literal handled incorrectly |
| Date: | Wed, 30 Aug 2017 15:30:55 +0800 |
| User-agent: | Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Thunderbird/52.2.1 |
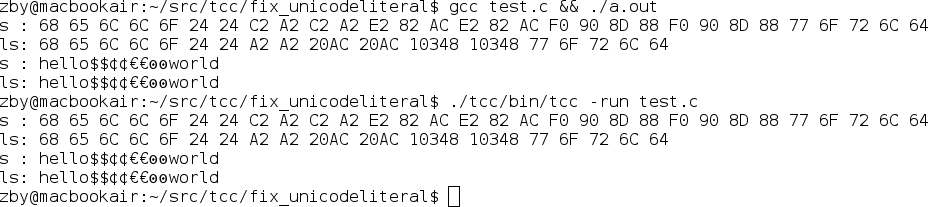
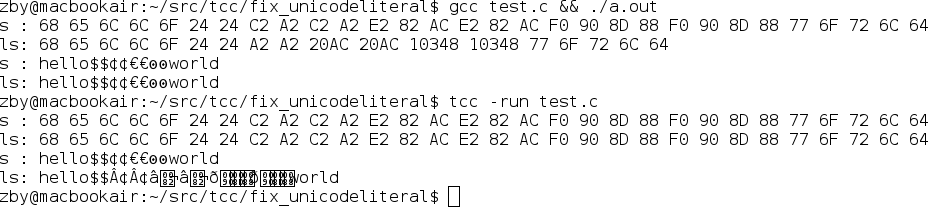
Hello,I found that when TCC processing wide string literal, it behaves like directly casting each char in original file to wchar_t and store them in wide string. This will work for ASCII chars. However, it might not work for real wide chars. For example: The Euro-sign (€, U+20AC) stored in UTF-8 is "E2 82 AC". In GCC, this char stored in wide string will be "000020AC". However, in TCC, this char is stored as 3 wide chars "000000E2 00000082 000000AC". I provided a patch, a test program and two screenshots that describe this problem, they are in attachments. I solve this problem by making assumptions that input charset is UTF-8. Although it's not a perfect solution, it's still better than "directly casting char to wchar_t". I'm wondering if that is appropriate, so please review the code carefully.
Thanks Zhang Boyang
![]() after-patch.png
after-patch.png
Description: PNG image
![]() before-patch.png
before-patch.png
Description: PNG image
![]() test.c
test.c
Description: Text Data
![]() utf8.patch
utf8.patch
Description: Text Data
| [Prev in Thread] | Current Thread | [Next in Thread] |
{kind=link}