{kind=link}
Description: PNG image
|
| From: | Juergen Sauermann |
| Subject: | Re: [Bug-apl] Performance optimisations: Results |
| Date: | Sun, 06 Apr 2014 16:32:10 +0200 |
| User-agent: | Mozilla/5.0 (X11; Linux i686; rv:17.0) Gecko/20130330 Thunderbird/17.0.5 |
|
Hi,
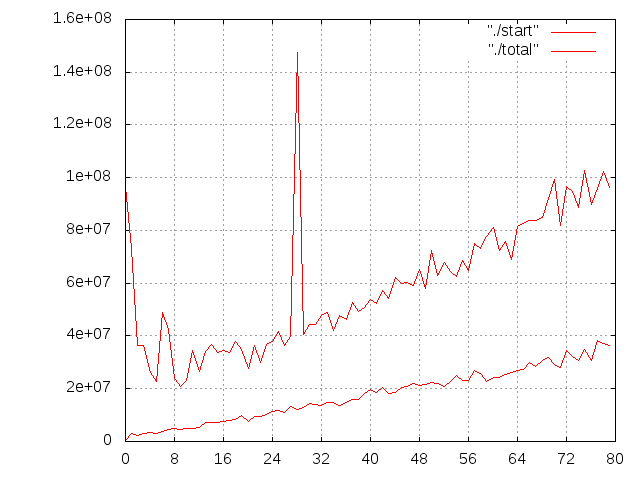
one more plot that might explain a lot. I have plotted the startup times and the total times vs. the number of cores (1024÷1024 array). For small core counts (i.e. < 6...10), the startup time is moderate and the total time decreases rapidly. For more cores, the total time increases again. This is most likely because the timer per core becomes negligible and the join time begins to dominate the total time. Both start and join times seem to be more-or-less linear with the number of cores which is probably because the master thread is doing all that. It would have been smarter to do the start and join in parallel which would then cost O(log P) instead of O(P) for P cores. /// Jürgen On 04/04/2014 04:52 PM, Elias Mårtenson wrote:
|
![]() start-total.png
start-total.png
Description: PNG image
| [Prev in Thread] | Current Thread | [Next in Thread] |