[Date Prev][Date Next][Thread Prev][Thread Next][Date Index][Thread Index]
FYI: optimizing out redundant index conversions
|
From: |
Jaroslav Hajek |
|
Subject: |
FYI: optimizing out redundant index conversions |
|
Date: |
Tue, 16 Feb 2010 15:36:47 +0100 |
hi all,
the following changeset
http://hg.savannah.gnu.org/hgweb/octave/rev/8b3cfc1288e2
aims to optimize out some redundant index conversions used by Octave.
Rationale:
Some built-in and compiled functions, such as find, sort, or sub2ind,
return index arrays. Because Octave internally operates on zero-based
arrays and the index arrays are returned as double matrices from
Matlab (for backward compatibility), Octave converts these zero-based
integer arrays to one-based double arrays when returning values to the
interpreter. More than half a year Octave employs an index cache
mechanism that eliminates the penalty for subsequent indexing. In
short, if you do (disregarding the fact that this can be done with a
logical mask):
idx = find (x < 0.5);
y = x(idx);
then since 3.2.x Octave eliminates the real-to-integer conversion and
checking for positiveness in the second statement, because after the
first statement both the one-based real matrix and zero-based integer
matrix are kept in memory. This has a very plausible impact on
performance, especially if idx is used for indexing more than once,
but the downside is that it requires more memory.
With the current patch, after the first statement only the zero-based
integer matrix will be kept in memory until idx is actually used for
something else than indexing (or trivial queries):
octave:1> x = rand (5);
octave:2> idx = find (x < 0.5);
octave:3> typeinfo (idx)
ans = lazy_index
octave:4> class (idx)
ans = double
I.e. lazy_index simply pretends it is a double matrix but postpones
the physical creation of the matrix until needed. Depending on whether
64-bit indices are used, this saves 66% or 50% of memory needed for
the index, as well as the redundant integer-to-real conversion, which
can be illustrated by this benchmark:
a = rand (4000) < 0.8;
try
find
sub2ind
end_try_catch
tic; i = find (a); a(i); toc
tic;
[i, j] = find (a);
k = sub2ind (size (a), i, j);
toc
with a recent tip, I get:
address@hidden:~/devel/octave/main> octave -q ttli.m
Elapsed time is 0.261135 seconds.
Elapsed time is 0.917434 seconds.
with the new patch, I get
address@hidden:~/devel/octave/main> ./run-octave -q ttli.m
Elapsed time is 0.171701 seconds.
Elapsed time is 0.593665 seconds.
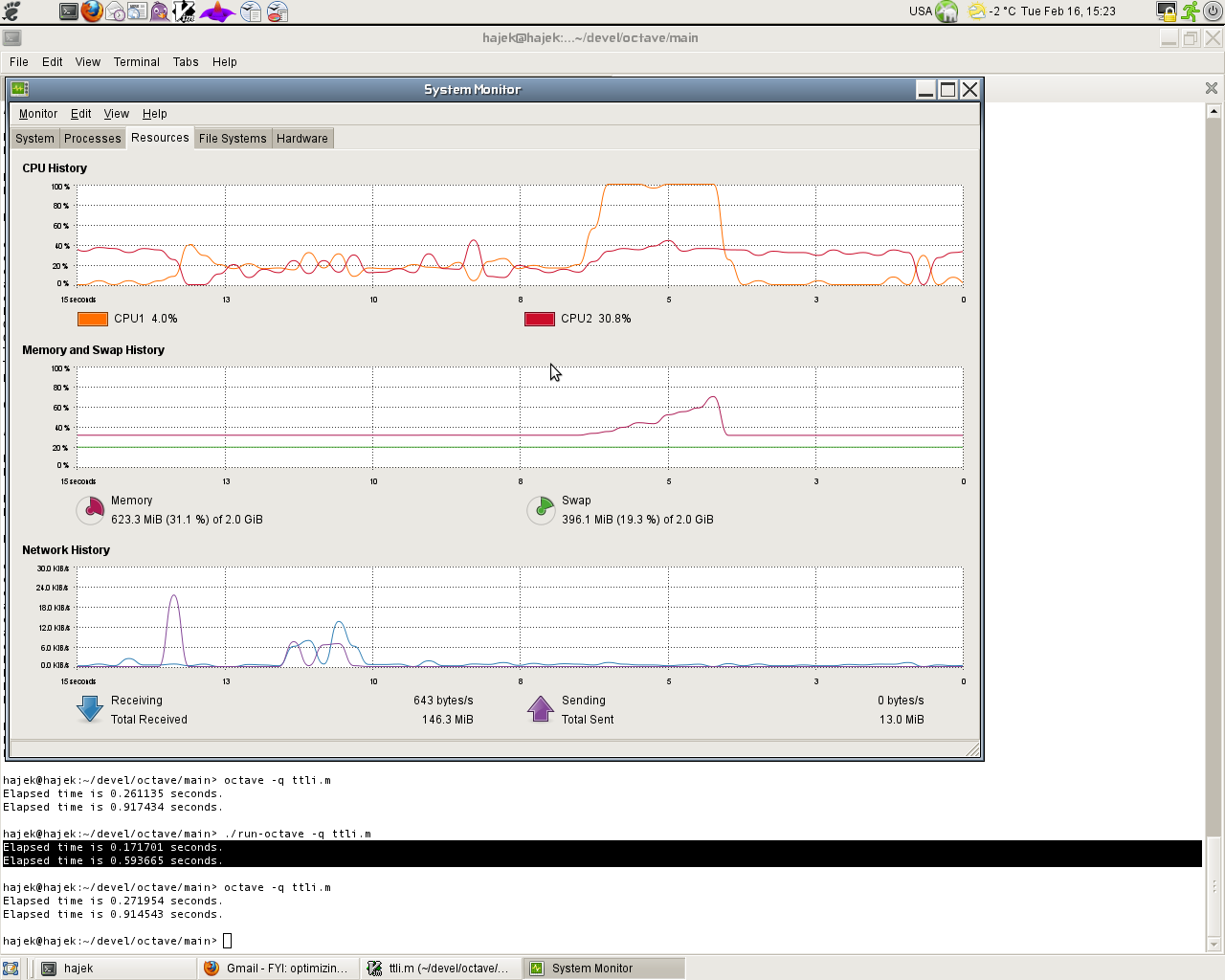
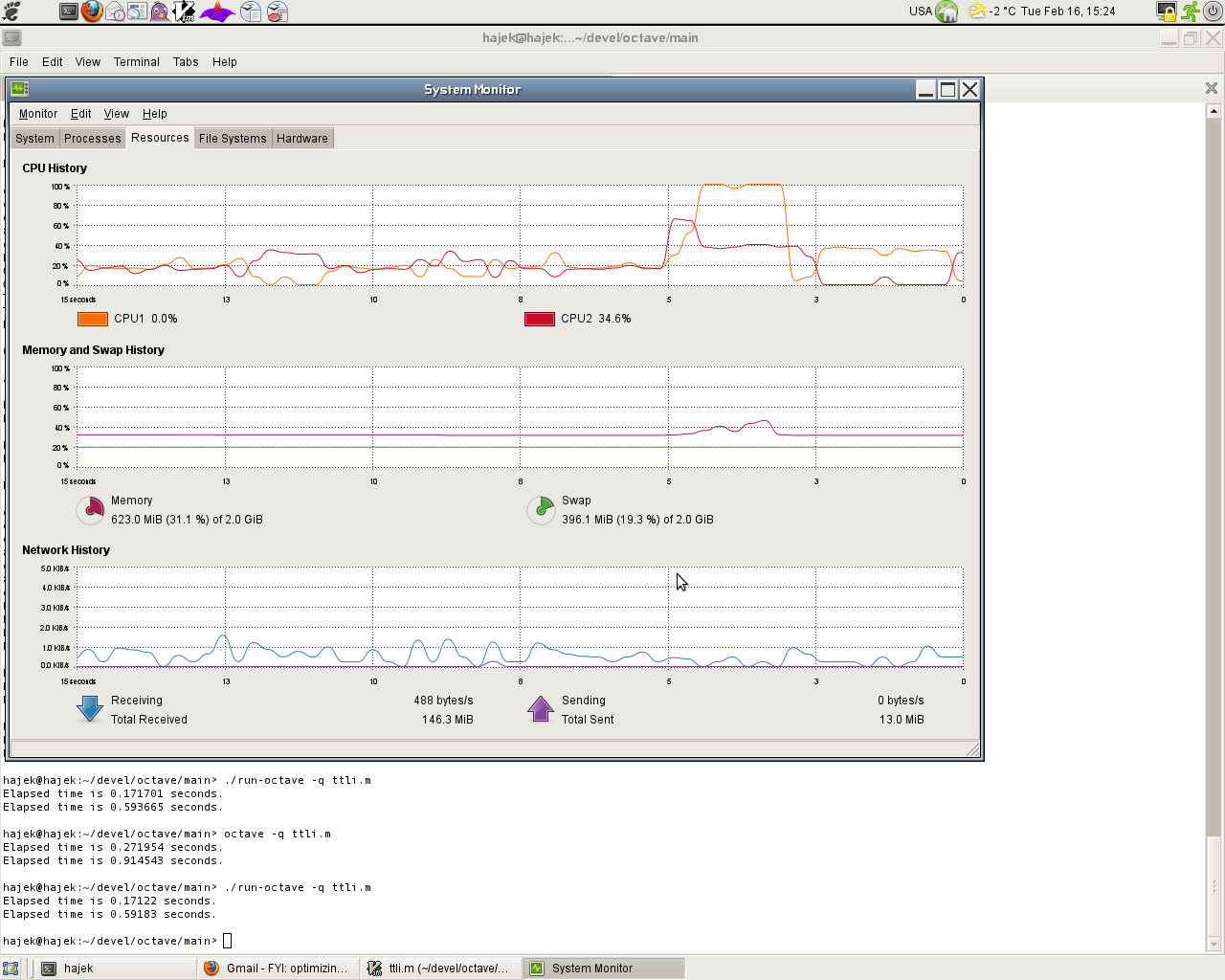
I also attach screenshots of memory usage as shown by GNOME system
monitor. It is apparent that in the second case (shot2) the usage is
much smaller. This should make some index manipulations (in particular
in the interpolating functions) more memory-efficient.
comments, further suggestions?
enjoy!
--
RNDr. Jaroslav Hajek, PhD
computing expert & GNU Octave developer
Aeronautical Research and Test Institute (VZLU)
Prague, Czech Republic
url: www.highegg.matfyz.cz
 shot1.png
shot1.png
Description: PNG image
shot2.png
Description: PNG image
| [Prev in Thread] |
Current Thread |
[Next in Thread] |
- FYI: optimizing out redundant index conversions,
Jaroslav Hajek <=
{kind=link}
{kind=link}