[Top][All Lists]
[Date Prev][Date Next][Thread Prev][Thread Next][Date Index][Thread Index]
[bug-libunistring] Re: [PATCH] join: support multi-byte character encodi
|
From: |
Bruno Haible |
|
Subject: |
[bug-libunistring] Re: [PATCH] join: support multi-byte character encodings |
|
Date: |
Mon, 20 Sep 2010 02:55:24 +0200 |
|
User-agent: |
KMail/1.9.9 |
[CCing bug-libunistring. This is a reply to
<http://lists.gnu.org/archive/html/coreutils/2010-09/msg00032.html>.]
Hi Pádraig,
> I was doing some performance analysis of the above patch
> and noticed it performed very well usually but not when
> ulc_casecoll or ulc_casecmp were called, when not in a
> UTF-8 locale. In fact it seemed to slow down everything
> by about 5 times?
>
> $ seq -f%010.0f 30000 | tee f1 > f2
>
> # with ulc_casecmp
> $ time LANG=en_US join -i f1 f2 >/dev/null
> real 0m1.281s
>
> # with ulc_casecoll
> $ time LANG=en_US join -i f1 f2 >/dev/null
> real 0m2.120s
>
> # with ulc_casecmp in UTF8 locale
> $ time LANG=en_US.utf8 join -i f1 f2 >/dev/null
> real 0m0.260s
>
> # with ulc_casecoll in UTF8 locale
> $ time LANG=en_US.utf8 join -i f1 f2 >/dev/null
> real 0m0.437s
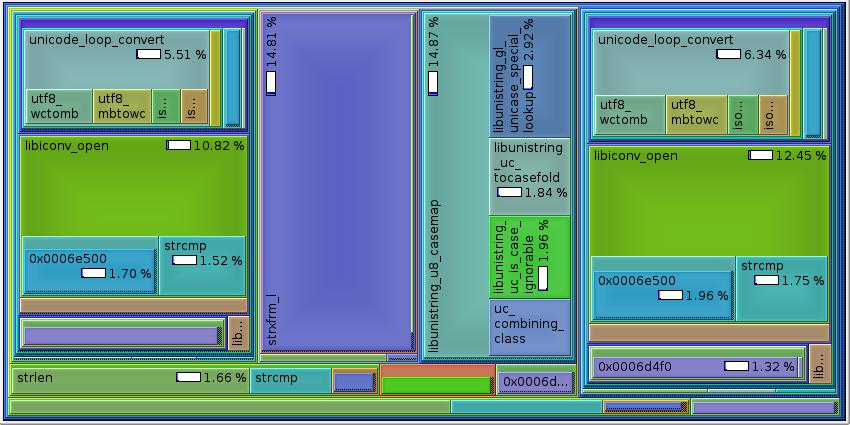
Thanks for the test case. I've produced a similar test case that operates
on the same data, in a way similar to 'join', and profiled it:
$ valgrind --tool=callgrind ./a.out
$ kcachegrind callgrind.out.*
> # Doing encoding outside gives an indication
> # what the performance should be like:
> # with ulc_casecoll in UTF8 locale
> $ time LANG=en_US.utf8 join -i <(iconv -fiso-8859-1 -tutf8 f1) \
> <(iconv -fiso-8859-1 -t utf8 f2) >/dev/null
> real 0m0.462s
This is an unfair comparison, because it throws overboard the requirement
that 'join' has to be able to deal with input that 'iconv' would not accept.
> A quick callgraph of ulc_casecoll gives:
>
> ulc_casecoll(s1,s2)
> ulc_casexfrm(s1)
> u8_conv_from_encoding()
> mem_iconveha(from,"UTF8",translit=true)
> mem_iconveh()
> iconveh_open()
> mem_cd_iconveh()
> mem_cd_iconveh_internal()
> iconv()
> iconveh_close()
> u8_casexfrm
> u8_ct_casefold()
> u8_casemap()
> u8_conv_to_encoding()
> ...
> memxfrm()
> ulc_casexfrm(s2)
> memcmp(s1,s2)
Unfortunately such a callgraph is not quantitative. I needed a
profiler to really make sense out of it.
The profiling showed me three things:
- The same string is being converted to UTF-8, then case-folded
according to Unicode and locale rules, then converted back to locale
encoding, and then strxfrm'ed, more than once. CPU time would be
minimized (at the expense of more memory use) if this was done only
once for each input line. It is not clear at this point how much
it must be done in join.c and how much help for this can be added
to libunistring.
- There are way too many iconv_open calls. In particular, while
ulc_casecmp and ulc_casecoll have to convert two string arguments
and could use the same iconv_t objects for both arguments, they
open fresh iconv_t objects for each argument.
- Additionally, every call to iconveh_open with target encoding UTF-8
calls iconv_open twice, where once would be sufficient.
> So one can see the extra overhead involved when not in UTF-8.
> Seems like I'll have to efficiently convert fields to utf8
> internally first before calling u8_casecoll()?
If there was a guarantee that all strings can be converted to UTF-8, yes.
But there is no such guarantee for 'join'. The keycmp function in
<http://lists.gnu.org/archive/html/coreutils/2010-09/msg00029.html> is
therefore actually wrong: It does not always satisfy the requirement
keycmp(A,B) < 0 && keycmp(B,C) < 0 ==> keycmp(A,C) < 0
The required handling of input strings that are not valid in the locale
encoding is more elaborate that I thought. I need to think more about
this issue.
Bruno
 test-u8_casecoll.c
test-u8_casecoll.c
Description: Text Data
- [bug-libunistring] Re: [PATCH] join: support multi-byte character encodings,
Bruno Haible <=